FAQs
We will briefly discuss key techniques in functional R programming which are best summarised by the table below. We will focus on purrr functionals and applications of function factories.
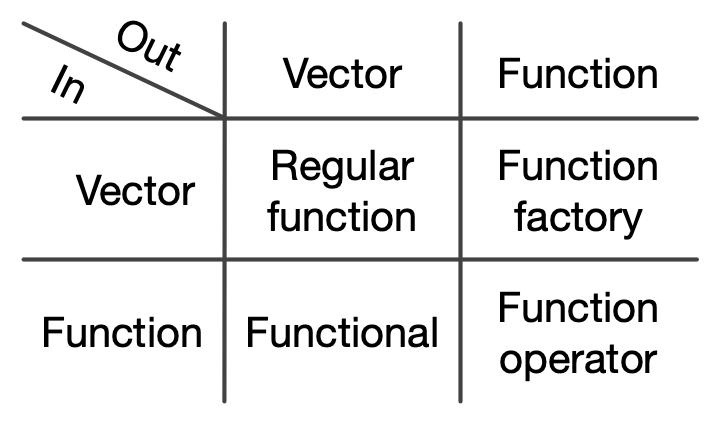
Source: Wickham (2019)
Functionals — purrr::map()
map() is the purrr version of lapply().
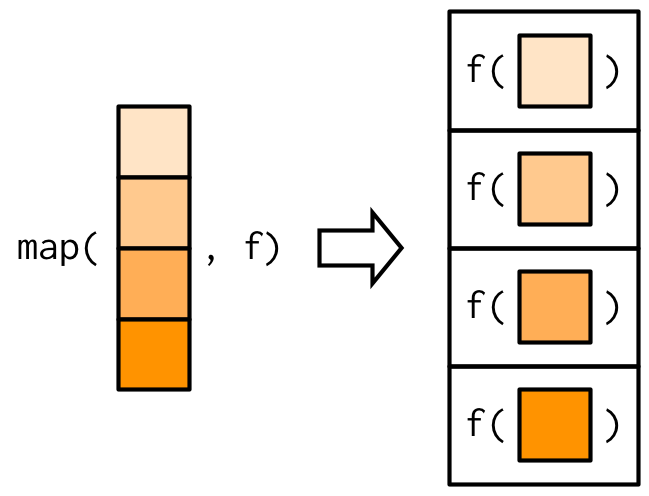
Source: Wickham (2019)
Example: map()
map(1:3, f) is list(f(1), f(2), f(3)).
triple <- function(x) x * 3map(1:3, triple)## [[1]]## [1] 3## ## [[2]]## [1] 6## ## [[3]]## [1] 9purrr::map_*() — Producing Atomic Vectors
There are helper functions which are more convenient if simpler data structures are required:
map_lgl(),map_int(),map_dbl(), andmap_chr()return an atomic vector of the specified typeBase R equivalents are
sapply()andvapply()
Example: map_*()
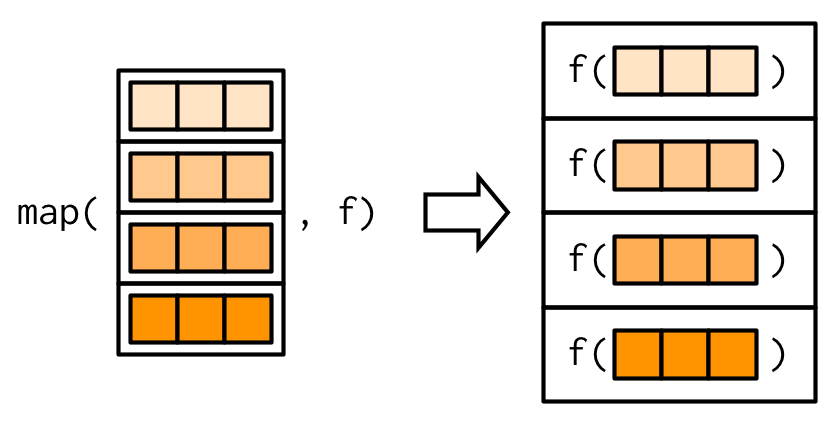
Source: Wickham (2019)
# check class of mtcars dataclass(mtcars)## [1] "data.frame"map_lgl(mtcars, is.double)## mpg cyl disp hp drat wt qsec vs am gear carb ## TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUEn_unique <- function(x) length(unique(x))map_int(mtcars, n_unique)## mpg cyl disp hp drat wt qsec vs am gear carb ## 25 3 27 22 22 29 30 2 2 3 6purrr::map_*() — Producing Atomic Vectors
Additional arguments to the mapping function may be passed after the function name.
We need to be careful with evaluation!
Example: mapping with additional arguments
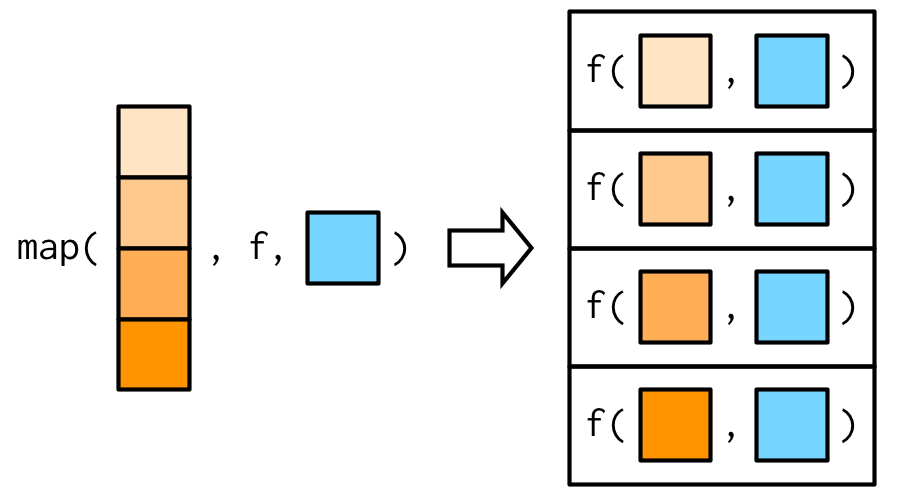
Source: Wickham (2019)
x <- list(1:5, c(1:10, NA))map_dbl(x, ~ mean(.x, na.rm = TRUE))## [1] 3.0 5.5More efficient:
map_dbl(x, mean, na.rm = TRUE)## [1] 3.0 5.5purrr::map_*() — Producing Atomic Vectors
Additional arguments are not decomposed: map_*() is only vectorised over (the data passed as) the first argument. Further (vector) arguments are passed along.
Example: mapping with additional arguments — ctd.
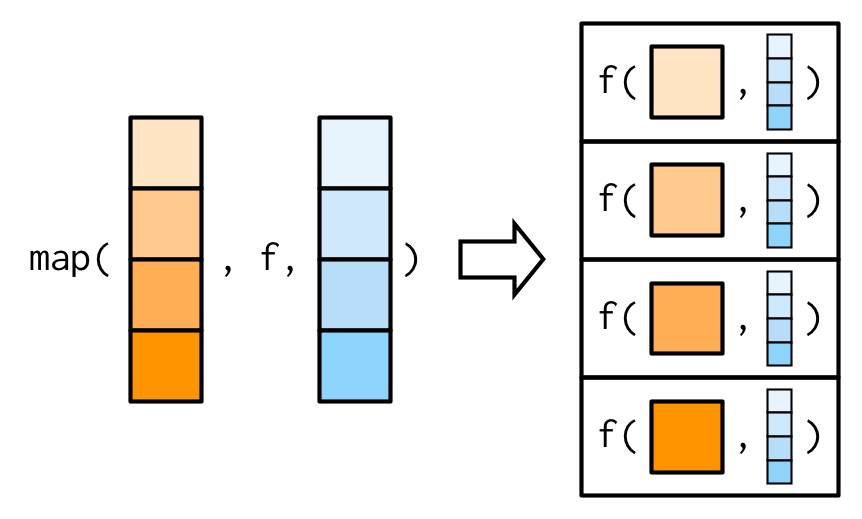
Source: Wickham (2019)
# Arg. 'mean' is recycledmap(1:3, rnorm, mean = c(100, 10, 1))## [[1]]## [1] 101.1215## ## [[2]]## [1] 101.324174 9.246503## ## [[3]]## [1] 101.8168982 10.5856532 0.9970042purrr::map_*() — Producing Atomic Vectors
Example: mapping over a different argument
Assume you'd like to investigate the impact of different amounts of trimming when computing the mean of observations sampled from a heavy-tailed distribution.
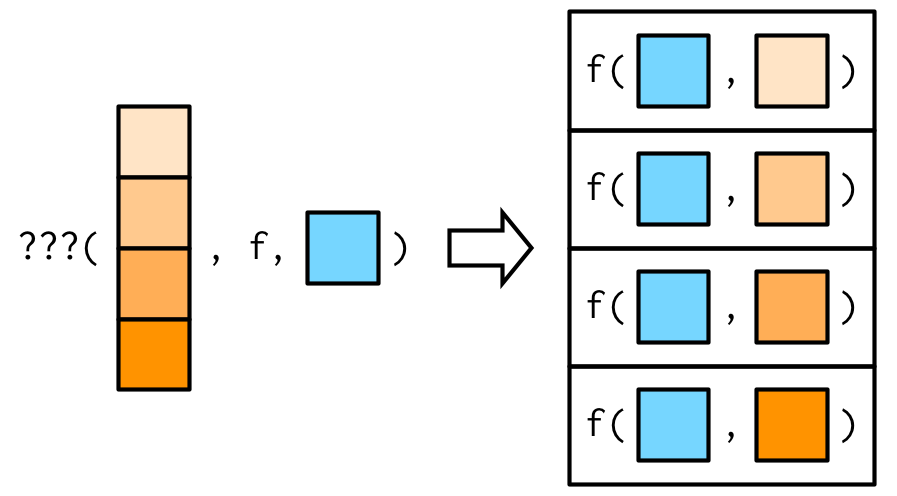
Source: Wickham (2019)
trims <- c(0, 0.1, 0.2, 0.5)x <- rcauchy(1000)We may switch arguments using an anonymous function:
map_dbl(trims, ~ mean(x, trim = .x))## [1] 0.624460050 0.006129521 0.038663335 0.075093275This is equivalent to:
map_dbl(trims, function(trim) mean(x, trim = trim))## [1] 0.624460050 0.006129521 0.038663335 0.075093275purrr::map2()
map2() is vectorised over two arguments.
Example: weighted mean using map2()
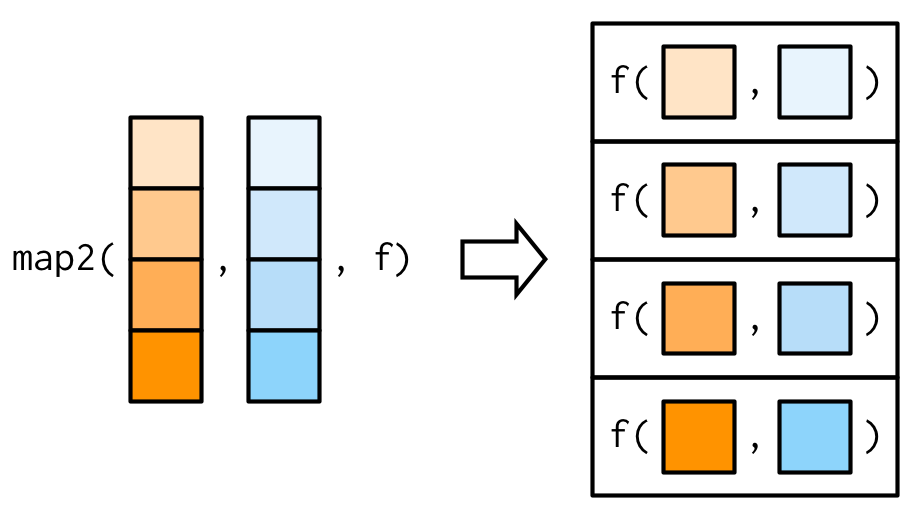
Source: Wickham (2019)
Let's generate lists of observations and associated weights.
set.seed(123)xs <- map(1:4, ~ runif(4))xs[[1]][[1]] <- NAws <- map(1:4, ~ rpois(4, 5) + 1)map2_dbl varies both xs and ws as inputs to weighted.mean().
map2_dbl(xs, ws, weighted.mean)## [1] NA 0.6625391 0.5968213 0.5287878purrr::map2()
Additional arguments may be passed just as with map().
Example: weighted mean using map2() — ctd.
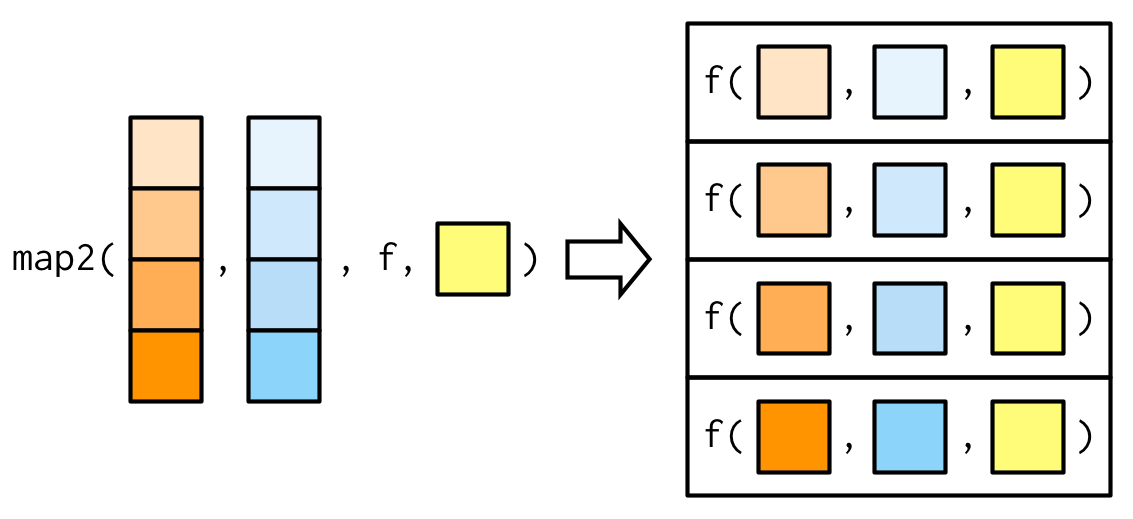
Source: Wickham (2019)
# passing na.rm = TRUEmap2_dbl(xs, ws, weighted.mean, na.rm = TRUE)## [1] 0.7355541 0.6625391 0.5968213 0.5287878purrr::map2()
Note that map2() also recycles inputs to ensure that they are the same length.
Example: weighted mean using map2() — ctd.
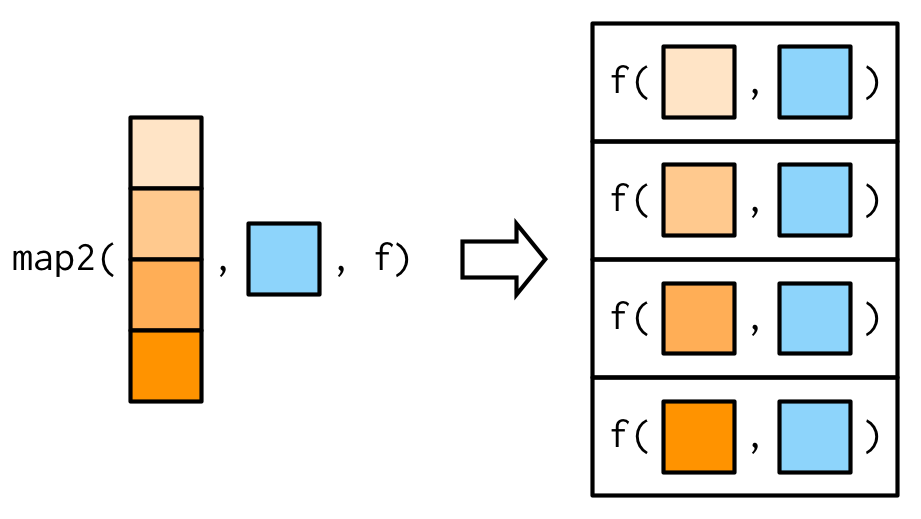
Source: Wickham (2019)
map2_dbl(1:6, 1, ~ .x + .y)## [1] 2 3 4 5 6 7purrr::walk()
walk()ignores the return value of.fand returns.xinvisibly. This is useful for functions that are called for their side-effects.There is no base R equivalent but wrapping
lapply()withinvisible()comes close
Example: assigning and passing objects
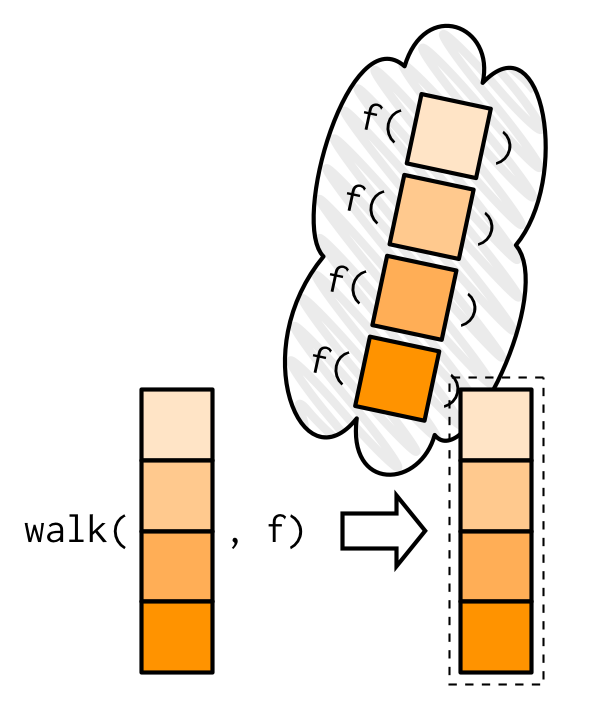
Source: Wickham (2019)
Assignment to an environment is a side-effect.

purrr::walk()
walk2() is a convenient alternative which is vectorised over two arguments.
Example: write to disc
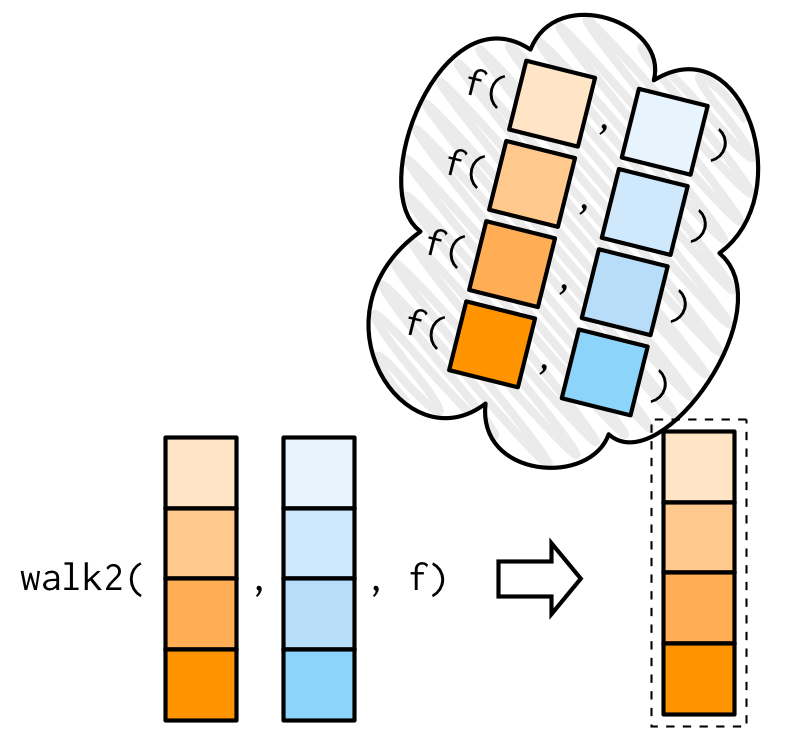
Source: Wickham (2019)
A common side-effect which needs two arguments (object and path) is writing to disk.
purrr::imap()
map(.x, .f)is essentially an analog tofor(x in xs) <apply .f to x and assign to list>for(i in seq_along(xs))andfor(nm in names(xs))are analogous toimap():imap(.x, .f)applies.fto values.xand indices or names derived from.x.
Example: named column means
imap() is a useful helper if we want to work with values along with variable names.
purrr::pmap()
pmap() generalises map() and map2() to p vectorised arguments. Thus pmap(list(x, y), f) is the same as map2(x, y, f).
Example: weighted mean with pmap()
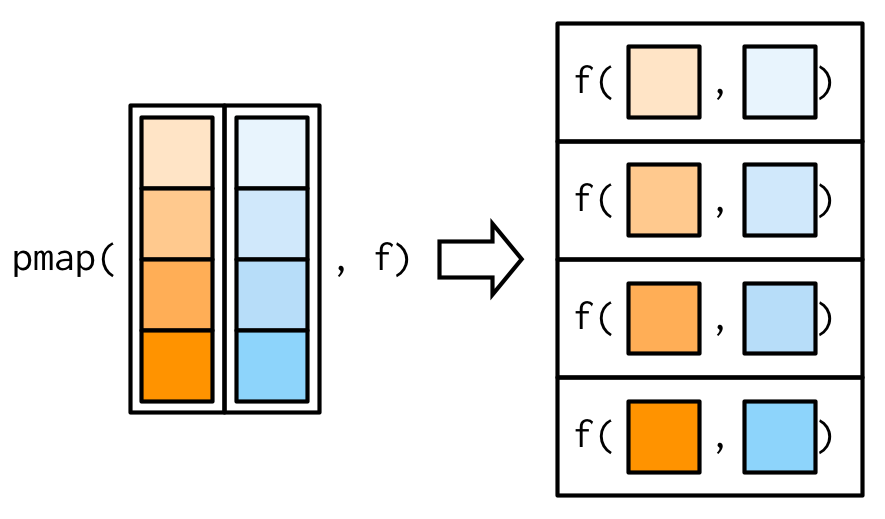
Source: Wickham (2019)
map2_dbl() behaves as pmap_dbl() in the two-argument case:
map2_dbl(xs, ws, weighted.mean)## [1] NA 0.6625391 0.5968213 0.5287878pmap_dbl(list(xs, ws), weighted.mean)## [1] NA 0.6625391 0.5968213 0.5287878purrr::pmap()
As before, additional arguments may be passed after .f and they are recycled, if necessary.
Example: weighted mean with pmap() — ctd.
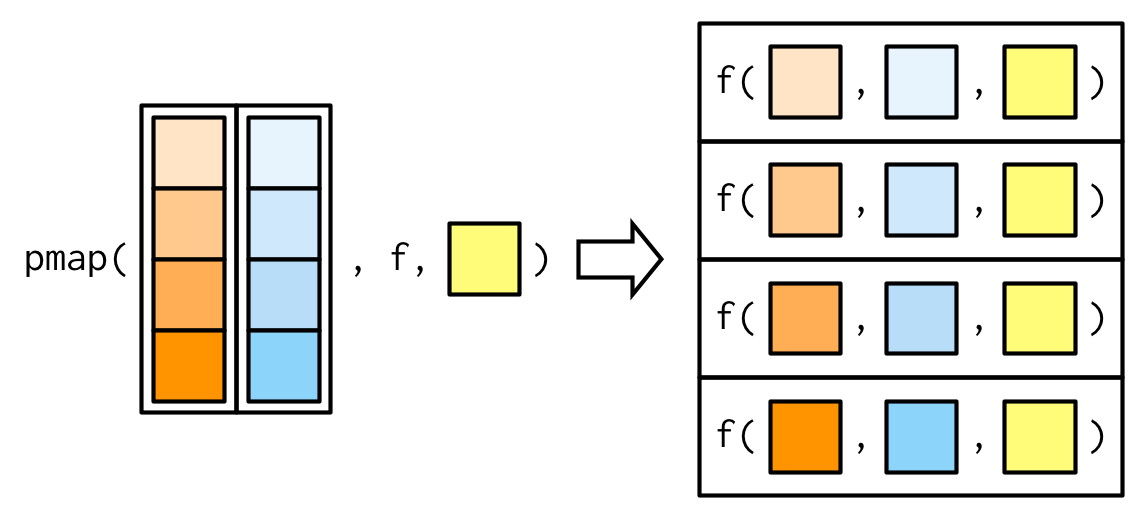
Source: Wickham (2019)
Now with the additional argument na.rm = TRUE:
pmap_dbl(list(xs, ws), weighted.mean, na.rm = TRUE)## [1] 0.7355541 0.6625391 0.5968213 0.5287878purrr::pmap()
Note that pmap() gives much finer control over argument matching as we may use named list. This is very convenient for working with complex list objects.
Example: argument matching using named list
Source: Wickham (2019)
We look at the trimmed mean example again.
trims <- c(0, 0.1, 0.2, 0.5)x <- rcauchy(1000)Varying the trim argument can be done by passing the values in a named list.
pmap_dbl(list(trim = trims), mean, x = x)## [1] -0.03231537 0.06072652 0.04464511 0.04482772purrr::pmap()
Remember that a data.frame is a list and thus can be passed to pmap() as a collection of inputs.
Example: pmap() with data.frame as input
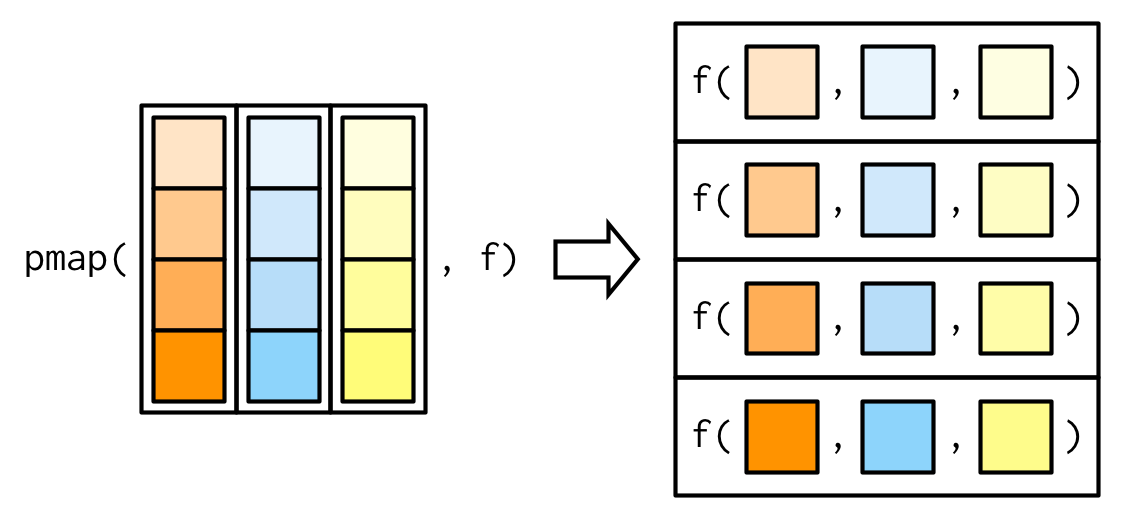
Source: Wickham (2019)
params <- tibble::tribble( ~ n, ~ min, ~ max, 1L, 0, 1, 2L, 10, 100)Column names match the arguments: we don't have to worry about their order.
pmap(params, runif)## [[1]]## [1] 0.4475701## ## [[2]]## [1] 21.72593 65.95534